Optimizing AI Inference at Character.AI (Part Deux)

At Character.AI, we’re building personalized AI entertainment. In order to offer our users engaging, interactive experiences, it's critical we achieve highly efficient inference, or the process by which LLMs generate replies. Our last post on this topic looked at several techniques that contribute to the performance and sustainability of our serving stack, such as multi-query attention (MQA), cross-layer KV-sharing, hybrid attention horizons, and int8 quantization. Those optimizations were primarily concerned with memory efficiency, and in particular how to reduce the KV cache to a manageable size.
In this post, we turn our focus to speed. Specifically, we show how our custom int8 attention kernel achieves strong performance for inference, both in the compute-bound setting of prefill and memory-bound case of iterative decoding. This performance rests not only on mastering the intricacies of GPU kernel programming but also on the following high-level ideas that make FlashAttention effective for int8 inference with MQA:
- Fusing dequantization into attention via warp-specialization: For reasons of accuracy, we want to compute score logits and probabilities in float precision, which necessarily entails dequantizing the QKV tensors for attention. We then eliminate the I/O cost associated with separate kernel launches by fusing the dequantization step into the attention kernel itself. To do this optimally, we leverage producer/consumer warp-specialization to effectively overlap dequantization with the matrix multiply-accumulate (MMA) instructions.
- Query head parallelization for MQA decoding: For short query sequence length, we can leverage the full extent of the MMA instruction tile in order to pack multiple query heads into each threadblock's attention computation and thereby achieve more parallelism. This idea can be viewed as complementary to the Flash-Decoding idea of splitting the kernel along the key/value sequence length. When combined, they bring the attention decoding speed much closer to the GPU’s theoretical maximum bandwidth for loading the KV cache, for both high batch size and large context.
Incorporating these two optimizations into a custom fork of FlashAttention-3 yields end-to-end inference speedup of up to 10% in prefill and 30% in decoding over a prior baseline that used a handwritten Triton attention kernel. The rest of this post will describe these two optimizations and then present microbenchmark results measured on an NVIDIA H100 SXM5 GPU.
FlashAttention-3 and int8 quantization
The main equation of self-attention is given by the formula
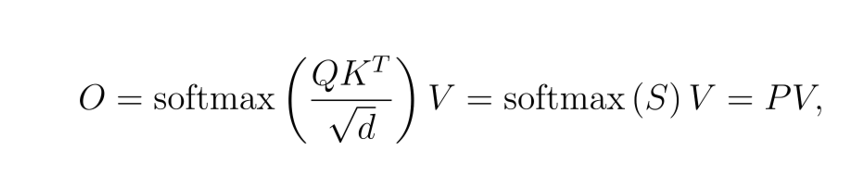
where Q, K, and V are the query, key, and value tensors, d is the head size, S and P are the score logits and probabilities, and O is the attention output. This formula is implicitly parallelized over the number of batches and heads in QKV.
Recall that the FlashAttention algorithm describes a certain structuring of this computation in which Q is tiled along its sequence length dimension and threadblocks load different tiles of Q from global memory into on-chip shared memory. Per threadblock, tiles of K and V are then successively loaded into shared memory buffers in order for the threadblock to compute its respective tile of O. Softmax is also replaced by online safe softmax. For our discussion, note that since FlashAttention does not materialize intermediate matrices to global memory, it can and does store S in float precision, while tiles of P are also computed as floats but downcasted to the native precision of QKV for the second matmul.
Now, if QKV are quantized in int8 precision together with float scaling factors, we have two basic options for an int8 attention kernel design:
- Half int8: Compute the first matmul using the int8 tensor cores and dequantize S using the scaling factors of Q and K. Then compute the second matmul using half-precision bf16 tensor cores and dequantize O using the scaling factor of V.As part of the fused FlashAttention kernel, this entails loading V in int8 format and then upcasting to bf16 in-kernel, while P is downcasted to bf16.
- Full int8: Compute both matmuls using the int8 tensor cores. This allows us to avoid in-kernel upcasting of V, but necessitates int8 quantization of P.
In both cases, the same number of bytes are loaded from the KV cache held in global memory. Thus, we expect options (1) and (2) to be approximately equal in speed for the memory-bound case of decoding. On the other hand, (2) will be faster in a compute-bound setting than (1). Nonetheless, to avoid potential regression in model quality, we opt for (1) as the base design. The following figure depicts one iteration of the compute main loop for half int8 attention:
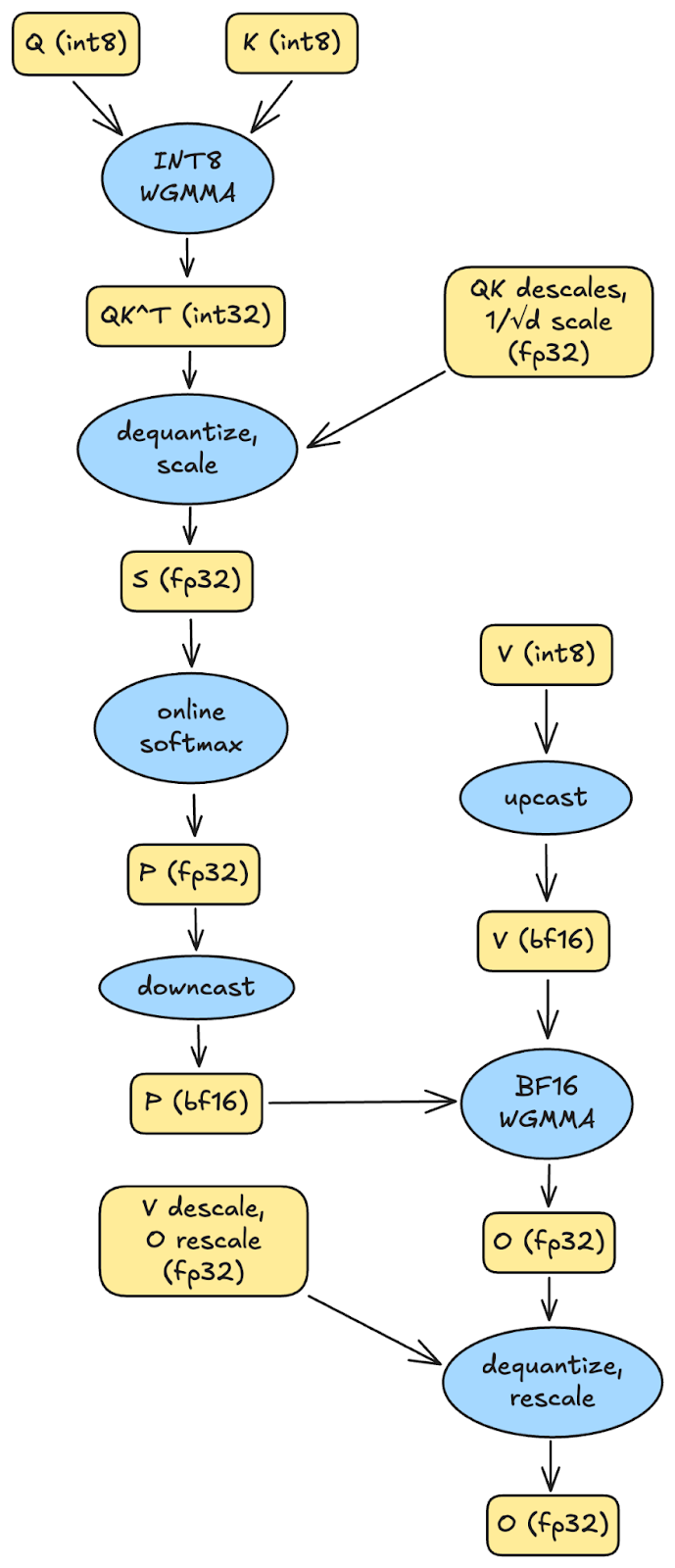
Next, we explain a general pattern for efficient in-kernel pre-processing of the KV tensors via warp-specialization. Warp-specialization is a CUDA design pattern that has separate warps take on the roles of either producers that load data, or consumers that compute on data. Generically, this facilitates the warp schedulers’ ability to overlap memory transfer and compute tasks. It also reduces resource contestation between warps, which will have very different register requirements as either producers or consumers.
The FlashAttention-3 algorithm adheres to a warp-specialized design. For fp16 or bf16 precision, a producer warp is responsible for issuing the TMA loads of tiles of K and V (in fact, issued by a single thread in the warp), while the remaining warps are delegated as consumers that compute all the matmuls and softmax and finally store the output. However, note that based on this it’s not clear where any pre-processing of the V tensor might be accommodated – in the producer or consumer path, and how?
To answer this question, we can take inspiration from the FA-3 algorithm in fp8 precision. For fp8 attention, the layout requirements for invoking the fp8 tensor cores on the PV matmul are opposite to the standard BSHD layout in which the V tensor is stored in global memory, necessitating transposing V as a pre-processing step. Ideally, transposing V should then be fused into the attention kernel. FA-3 does this as follows:
- The producer warp is extended to a producer warpgroup (i.e., a set of 4 contiguous warps) in which the warps act cooperatively to transpose tiles of V as they are loaded into shared memory by TMA. (For expert readers: strictly speaking, the fp16/bf16 FA-3 kernel also has a producer warpgroup since dynamic reallocation of registers is warpgroup-scoped, but with the three additional warps not doing any work.)
- Transpose of V is done out-of-place, with the transposed tiles stored in a new shared memory buffer.
- Added synchronization logic is introduced to handle how the producer warpgroup acts both as a producer for the consumer warps and a consumer of the TMA load of V.
Observe that there is nothing specific about transposition in this design; any pre-processing step involving out-of-place memory transfer would fit equally well in the above. As such, for our half int8 version of FA-3, we can reuse almost all of the code that comprises the load method for fp8 FA-3. The only difference is that we replace the functor object that performs the transpose with one that does upcasting on V instead.
We can then use inter-warpgroup pingpong scheduling and intra-warpgroup matmul-softmax overlapping in the same way as in FA-3 to achieve good performance for the half int8 attention kernel in terms of FLOPs/s. Microbenchmarks show its FLOPs/s lying approximately halfway between those for FA-3 in bf16 and fp8 precision.
Parallelizing across query heads for multi-query attention
For decoding, the query sequence length is short, typically equal to just one or a few tokens. In this case, the standard way of tiling the attention computation will waste a large amount of the MMA instruction tile. Indeed, the WGMMA instruction used to target the Hopper tensor cores extends to a width of 64 per warpgroup for the first operand's outer dimension. Given two consumer warpgroups, as is usually chosen to maximize register usage, each threadblock would then be computing tiled matmuls with 128 rows such that all but the first few rows of the output are discarded!
On the other hand, FlashAttention normally parallelizes threadblocks over the number of batches and query heads. However, for decoding, we aim to achieve kernel speed at the GPU's bandwidth purely as a function of loading the KV cache. Then in the case of multi-query attention, threadblocks reading the same KV head should ideally be combined into a single threadblock to avoid superfluous loads from global memory (notwithstanding L2 cache effects).
We can do this by having each threadblock load multiple query heads per batch and pack them together into its Q tile. For example, we could have 16 query heads and 4 query tokens, packed as the Q tile for an attention computation that uses 1 warpgroup. For head dimension 128, this would look as follows, with each color representing a different query head and each subtile corresponding to one query token:

In contrast, if we run attention without query head packing, we would have 16 separate threadblocks in which we only use the first 4 of the 64 rows in the WGMMA operand tile for the attention computation. For instance, the 8th query head would have its query tile display as follows, where the striped region holds undefined values and is wasted by the computation:

The simple insight is that since softmax is done row-wise, we can use the same loop over tiles of KV to compute outputs over multiple query heads in parallel, internal to the threadblock. For large batch sizes, such as those matching the number of streaming multiprocessors (SMs), this strategy reduces the total number of waves by a factor of N, where N is the ratio of query heads to KV heads.
For small batch sizes, we also need to contend with low GPU occupancy, which this technique doesn't address. Rather, we split the kernel along the KV sequence length to introduce more parallelism, as described in the Flash-Decoding blog post. It’s then straightforward to combine the split KV and query head packing techniques to define the complete FA-3 inference kernel. For tuning the unified kernel, we observe that the reduction in threadblock count achieved by query head packing leads us to increase the number of splits used to fill out a wave. Finally, we note that FlashAttention-3 also recently added support for query head packing in its codebase.
Benchmarks
We present microbenchmarks of the half int8 attention kernel measured on an H100 SXM5 GPU with CUDA version 12.4. We fix the model architecture parameters to have head dimension 128, 16 query heads, and 1 KV head.
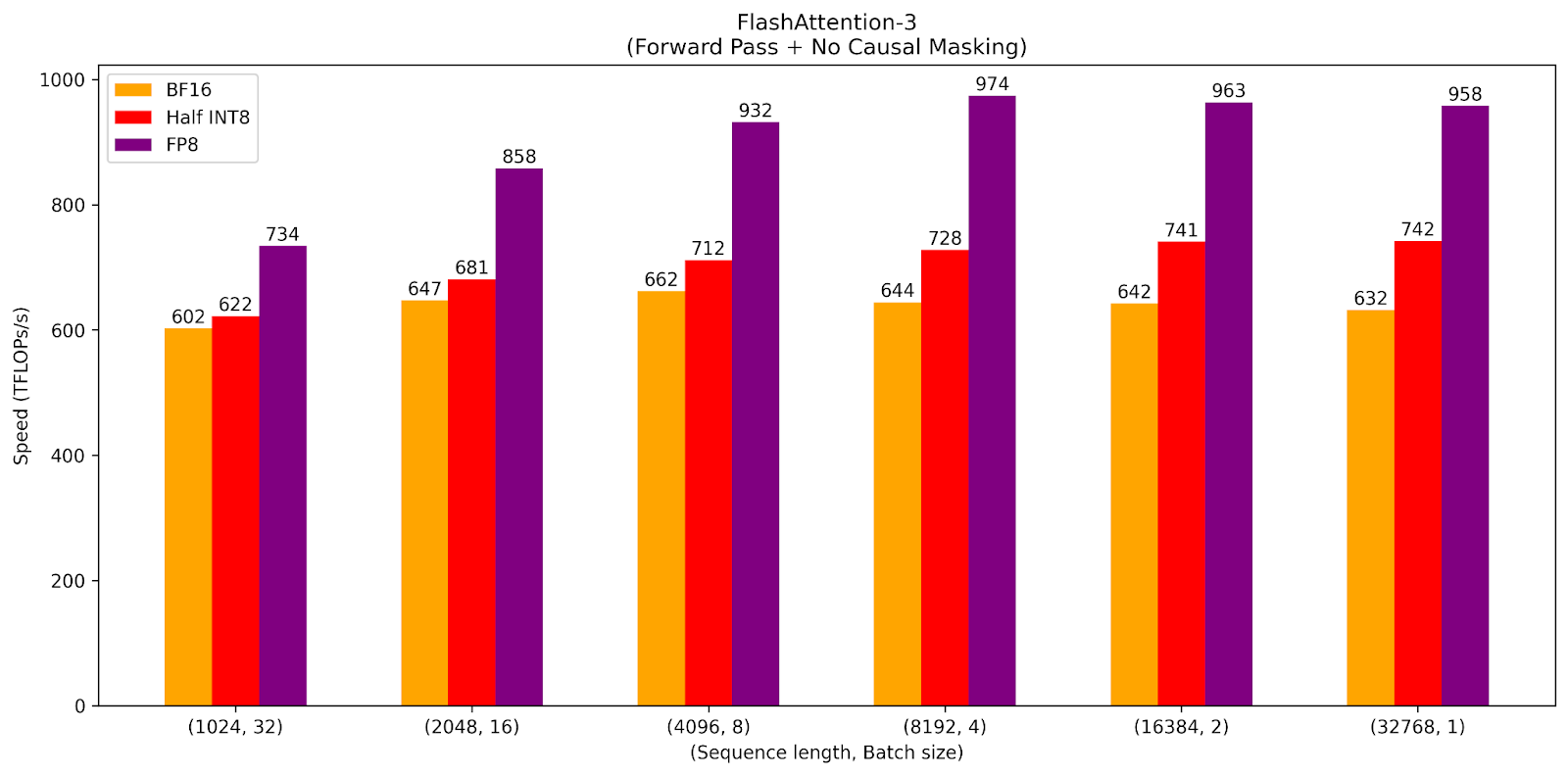
Table 1: TFLOPs/s benchmarks for FA-3 without causal masking, arranged by datatype.
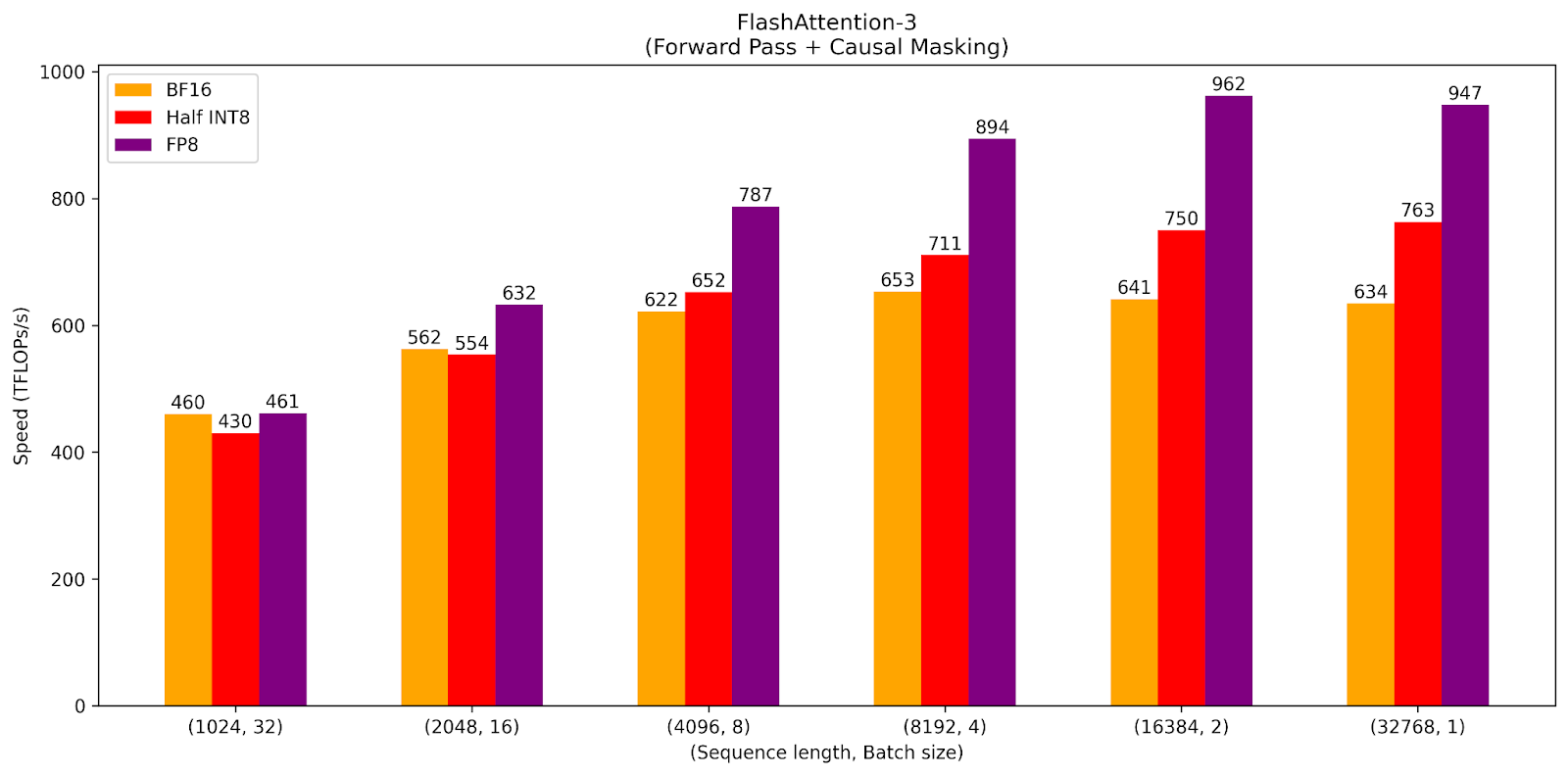
Table 2: TFLOPs/s benchmarks for FA-3 with causal masking, arranged by datatype.
In the compute-bound setting, we see the expected separation of bf16, half int8, and fp8 TFLOPs/s performance for large sequence lengths. However, for short sequence lengths, we see this effect as being less pronounced or even reversed. We expect to make further progress on optimizing the scheduling for the int8 kernel to improve these cases. We also plan to incorporate recent improvements in FA-3 to lift performance across the board.
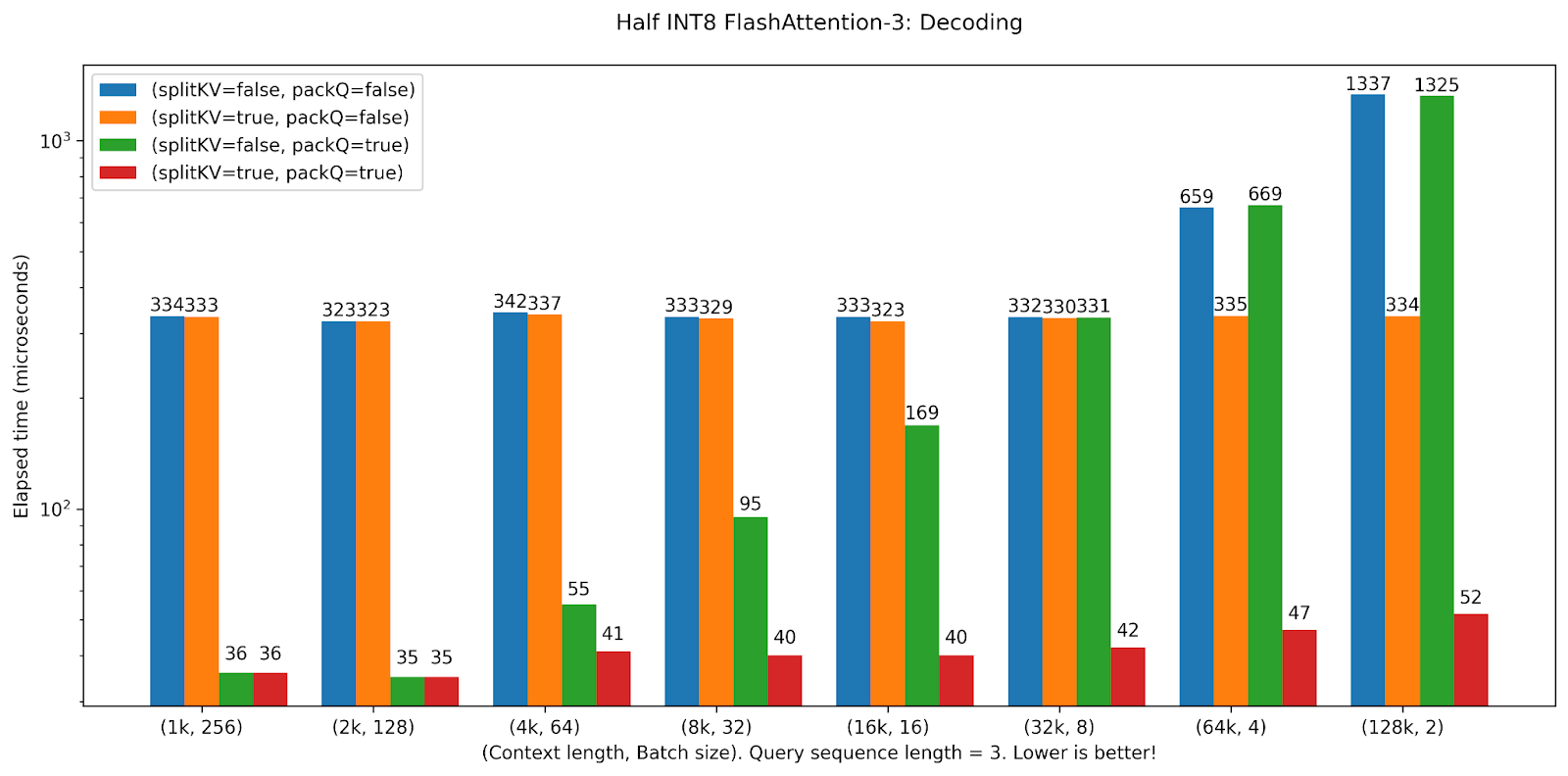
Table 3: Elapsed time (microseconds) benchmarks for FA-3 in decoding setup. Query sequence length equals 3. Bandwidth is measured with respect to the last column (splitKV=packQ=true) in terms of loading the KV cache held in int8 precision.
In the memory-bound setting, we observe a few interesting patterns. First, beyond some threshold, the time linearly increases as a function of batch size decreasing when the split kernel is not enabled, due to lack of GPU occupancy. This threshold is encountered earlier when packing query heads due to the associated reduction in threadblock count. Second, when the split KV kernel is enabled, the kernel time is near constant as a function of the product of context length and batch size, with only a small dropoff as context length increases when packing query heads. This regression is explained by the added overhead of the post-processing reduction kernel that combines splits. Third, the reduction in time achieved by query head packing is largest when batch size is large, up to 9.3x and falling to 6.4x.
Enhancing AI Conversations for Everyone
Our highly optimized attention kernel, combined with innovations across our serving stack, has achieved unprecedented efficiency in LLM inference. The result is a better experience for our rapidly growing global community of over 20 million users — enabling more responsive Characters, smoother conversations, and richer interactions at scale.
If you're passionate about optimizing ML systems and solving complex engineering challenges that impact millions of users, we'd love to hear from you. Join us in building the future of AI interactions at Character.AI!
This post was authored in collaboration with Jay Shah from Colfax Research.