Optimizing AI Inference at Character.AI

At Character.AI, we're building toward AGI. In that future state, large language models (LLMs) will enhance daily life, providing business productivity and entertainment and helping people with everything from education to coaching, support, brainstorming, creative writing and more.
To make that a reality globally, it's critical to achieve highly efficient “inference” – the process by which LLMs generate replies. As a full-stack AI company, Character.AI designs its model architecture, inference stack and product from the ground up, enabling unique opportunities to optimize inference to be more efficient, cost-effective and scalable to a rapidly growing, global audience.
Today we serve more than 20,000 inference queries per second. To put this in perspective, this is roughly 20% of the request volume served by Google Search, which processes around 105,000 queries per second according to third party estimates (Statista, 2024).
We can sustainably serve LLMs at this scale because we have developed a number of key innovations across our serving stack. In this blog post, we share some of the techniques and optimizations we have developed over the past two years and recently employed.
Memory-efficient Architecture Design
The key bottleneck of LLM inference throughput is the size of the cache of attention keys and values (KV). It not only determines the maximum batch size that can fit on a GPU, but also dominates the I/O cost on attention layers. We use the following techniques to reduce KV cache size by more than 20X without regressing quality. With these techniques, GPU memory is no longer a bottleneck for serving large batch sizes.
1. Multi-Query Attention. We adopt Multi-Query Attention (Shazeer, 2019) in all attention layers. This reduces KV cache size by 8X compared to the Grouped-Query Attention adopted in most open source models.
2. Hybrid Attention Horizons. We interleave local attention (Beltagy et al., 2020) with global attention layers. Local attention is trained with sliding windows, and reduces the complexity from O(length2) to O(length). We found that reducing attention horizon to 1024 on most attention layers does not have a significant impact on evaluation metrics, including the long context needle-in-haystack benchmark. In our production model, only 1 out of every 6 layers uses global attention.
3. Cross Layer KV-sharing. We tie the KV cache across neighboring attention layers, which further reduces KV cache size by a factor of 2-3x. For global attention layers, we tie the KV cache of multiple global layers across blocks, since the global attention layers dominate the KV cache size under long context use cases. Similar to a recent publication (Brandon et al., 2024), we find that sharing KV across layers does not regress quality.

Stateful Caching
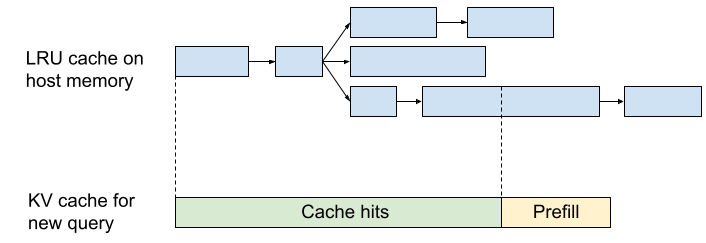
One of our key innovations is an efficient system for caching attention KV on host memory between chat turns. On Character.AI, the majority of chats are long dialogues; the average message has a dialogue history of 180 messages. As dialogues grow longer, continuously refilling KV caches on each turn would be prohibitively expensive.
To solve this problem, we developed an inter-turn caching system. For every prefilled prefix and generated message, we cache the KV values on host memory and retrieve them for future queries. Similar to RadixAttention (Zheng et al., 2023), we organize cached KV tensors in a LRU cache with a tree structure. The cached KV values are indexed by a rolling hash of prefix tokens. For each new query, a rolling hash is calculated for each prefix of the context, and the cache is retrieved for the longest match. This allows reusing the cache even for partially matched messages.
At a fleet level, we use sticky sessions to route the queries from the same dialogue to the same server. Since our KV cache size is small, each server can cache thousands of dialogues concurrently. Our system achieves a 95% cache rate, further reducing inference cost.
Quantization for Training and Serving
We use int8 quantization on model weights, activations, and attention KV cache. To support this, we implemented customized int8 kernels for matrix multiplications and attention. Different from commonly adopted "post-training quantization" techniques, we natively train our models in int8 precision, eliminating the risk of training/serving mismatch while also significantly improving training efficiency. Quantized training is a complex topic on its own, and we will address it in future posts.
Building the Future Together
Efficient inference is crucial for scaling AI systems and integrating them seamlessly into our daily lives. Taken together, the innovations discussed above achieve unprecedented efficiency and reduce inference costs to a level that makes it far easier to serve LLMs at scale. We have reduced serving costs by a factor of 33 compared to when we began in late 2022. Today, if we were to serve our traffic using leading commercial APIs, it would cost at least 13.5X more than with our systems.
Yet this is just the beginning. At Character.AI, we're excited to continue building a future where LLMs are driving innovation and enhancing experiences for everyone worldwide. Join us on this exciting journey as we continue to push the limits of what's possible with AI. Together, we are creating a future where efficient and scalable AI systems are at the heart of every interaction.